image de disparité pour le bâtiment
image de disparité pour la zone urbaine
Tout d'abord, le caractère très bruité de l'image d'amplitude radar va obliger à mettre en place un filtrage.
Ensuite les images d'amplitude à traiter sont énormément texturées. Une texture répond aux mêmes propriétés statistiques : sur une zone limitée, les densités sont étudiées selon les règles de la statistique ainsi l'homogénéité ou l'hétérogénéité d'une zone peuvent être quantifiée ou distribuée en une ou plusieurs populations.
En se fondant sur ces remarques, nous avons commencé par explorer les différentes possibilités qu'offre la statistique. Nous avons donc étudié une segmentation basée sur le calcul de la disparité puis sur celui de la variance.
description théorique
Cette méthode consiste à comparer, dans une fenêtre se déplaçant sur l'image, la moyenne des niveaux de gris sur cette fenêtre et la valeur du niveau de gris du pixel central. On obtient alors:
- un résultat élevé si le pixel central n'a pas une valeur caractéristique de la région où il se trouve
- un résultat faible si le pixel appartient bien à la région.
On doit cependant adapter cette méthode, en effet les images sont trop texturées pour l'appliquer telle quelle et la valeur du pixel central n'est pas représentative.
Nous avons donc essayé deux formes améliorées:
- deux fenêtres de même taille placées de chaque côté de la ligne image du pixel traité. La différence se fait alors entre la moyenne des deux fenêtres.
- trois fenêtres de même taille : une fenêtre centrée sur le pixel à traiter et les deux autres au-dessus et en dessous. On calcule alors la différence entre la moyenne du centre et celle du dessus puis du dessous. On conserve la valeur la plus forte.
remarque algorithmique
L'utilisation de fenêtres a certaines conséquences fâcheuses sur l'image résultat. En effet, la taille des fenêtres va avoir un impact sur le nombre de pixels manipulés et donc sur la taille de l'image de sortie.
On affiche directement l'histogramme pour pouvoir dire rapidement si l'on peut discerner des partitions différentes. Si on peut voir deux gaussiennes dont les moyennes sont éloignées alors le procédé est discriminant. Sinon la segmentation a échoué.
présentation des résultats
Les résultats obtenus ne conviennent pas. Ceci est dû au fait que l'image d'amplitude traitée est beaucoup trop texturée pour cette méthode. De plus la faible taille de certaines des images limite la dimension des fenêtres. On commence à distinguer la frontière entre les zones planes et la zone de repliement sur l'image de gauche. Cela reste toutefois insuffisant.
|
|
|
|
image de disparité pour le bâtiment |
image de disparité pour la zone urbaine |
description théorique
Le calcul de la variance s'effectue sur une fenêtre centrée sur le pixel traité :
![]()
présentation des résultats obtenus
Nous n'aboutissons pas aux résultats escomptés. Comme pour la disparité, l'exploitation de ces résultats n'est pas réalisable. Si on distingue la zone de recouvrement sur l'image de gauche, cela n'est pas utilisable pour extraire les frontières.
|
|
|
|
image de variance sur le bâtiment |
image de variance sur la zone urbaine |
Cette méthode consiste en la combinaison de plusieurs traitements :
- on applique à deux reprises, l'une à la suite de l'autre, le filtre médian de taille 5x5;
- puis on classe les pixels afin de segmenter en régions grâce à la méthode Isodata.
description théorique
Le filtre médian réalise un lissage de l'image en gardant les contours. Pour renforcer cette action, on emploie deux fois ce filtre.
Le but ensuite est de repérer les frontières des régions, c'est à dire les lignes de discontinuité. Pour résoudre cela on va classer l'image en deux partie :
- le fond qui symbolise le sol, et où l'amplitude est homogène car il n'y a pas d'aspérités perturbatrices
- les régions correspondant soit à des zones de recouvrement, soit aux immeubles.
Dans cette optique nous nous servons d'une méthode de classification non supervisée, c'est à dire qu'aucun échantillon définissant les classes n'est fournit. Le nombre de classes étant fixé, la méthode des nuées dynamiques, sur laquelle est basé l'algorithme Isodata, est tout à fait désignée. Elle consiste à choisir un critère global de différenciation. On définit des noyaux initiaux, c'est à dire une valeur de critère représentative de chaque partition. On va alors calculer la distance de chaque élément de l'image par rapport à tous les noyaux. On affecte le point à la classe dont le noyau est le plus proche. Une fois tous les pixels répartis, on recalcule les noyaux qui génèrera une meilleur partition. On itère le processus jusqu'à la stationnarité.
Une fois la classification finie, on a une image binarisée, puisqu'il y a deux classes. On a différencié le fond des bâtiments. Cependant ce n'est pas encore le résultat final. Effectivement , on doit repérer les frontières de passage entre les deux partitions. Elles représentent les zones de discontinuité. Pour cela il suffit de ne garder que les pixels dont les voisins à droite et à gauche ont un niveau de gris différent. Nous justifierons, lors du chapitre consacré à la fusion, les valeurs des pixels affectées aux deux classes.
présentation des résultats
L'application des deux filtres médian 5*5 permet d'uniformiser les niveaux de gris de pixels formant les régions du sols et des toits. Les éléments formant le sol ont tendance à avoir des valeurs faibles, alors que les partitions représentant les toits convergent vers des valeurs fortes. Ceci autorise à penser qu' une classification basée sur la moyenne des niveaux de gris permettra de séparer le sol des bâtiments. En effet si on a des valeurs faibles pour le sol alors la moyenne sera faible par contre les toits auront une moyenne élevées.
|
|
|
|
après deux convolutions du filtre médian, image du bâtiment |
après deux convolutions du filtre médian, image de zone urbaine |
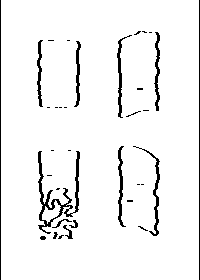
Sur l'image de gauche, on a bien isolé la zone de recouvrement. Sur l'image de droite, l'application du procédé de classification amélioré aboutit à l'obtention des frontières des bâtiments. On peut remarquer qu'ils ne sont pas rectilignes contrairement à ce que l'on voit à l'oeil sur l'image d'amplitude. On peut alors supposer que certains des pixels formant la discontinuité seront oubliés. Mais l'épaisseur de la frontière corrigera certainement en grande partie cette erreur.
On observe aussi un problème au niveau du bâtiment en bas à gauche. La partie inférieur de la région n'était pas bien défini, ce qui entraîne une mauvaise classification. L'importance de cette erreur sera réduite comme nous le verrons lors de la fusion.
|
|
|
|
bâtiment après Isodata |
zone urbaine après Isodata |
![]()
![]()
![]()